Général
Azure Files est un stockage cloud, accessible via SMB par une machine locale, ou une VM Azure.
Azure Files peut stocker plusieurs types de ressources, comme les conteneurs blob, mais je m’intéresse ici uniquement aux partages de fichiers.
Il y’a également la possibilité de créer des partages NFS, mais je n’aborde pas ce cas ici. Un partage est accessible soit par SMB soit par NFS, mais pas les 2 en même temps.
Guide de planification général Azure Files
https://learn.microsoft.com/en-us/azure/storage/files/storage-files-planning
Quelques considérations
MS conseille de ne pas mélanger les différents types de ressources au sein d’un même compte de stockage (si il contient un partage Azure Files, alors il est déconseillé d’y mettre un stocke blob par exemple).
Dans la mesure du possible, essayer de ne mettre qu’un seul partage par compte de stockage (chaque partage aura son propre compte de stockage).
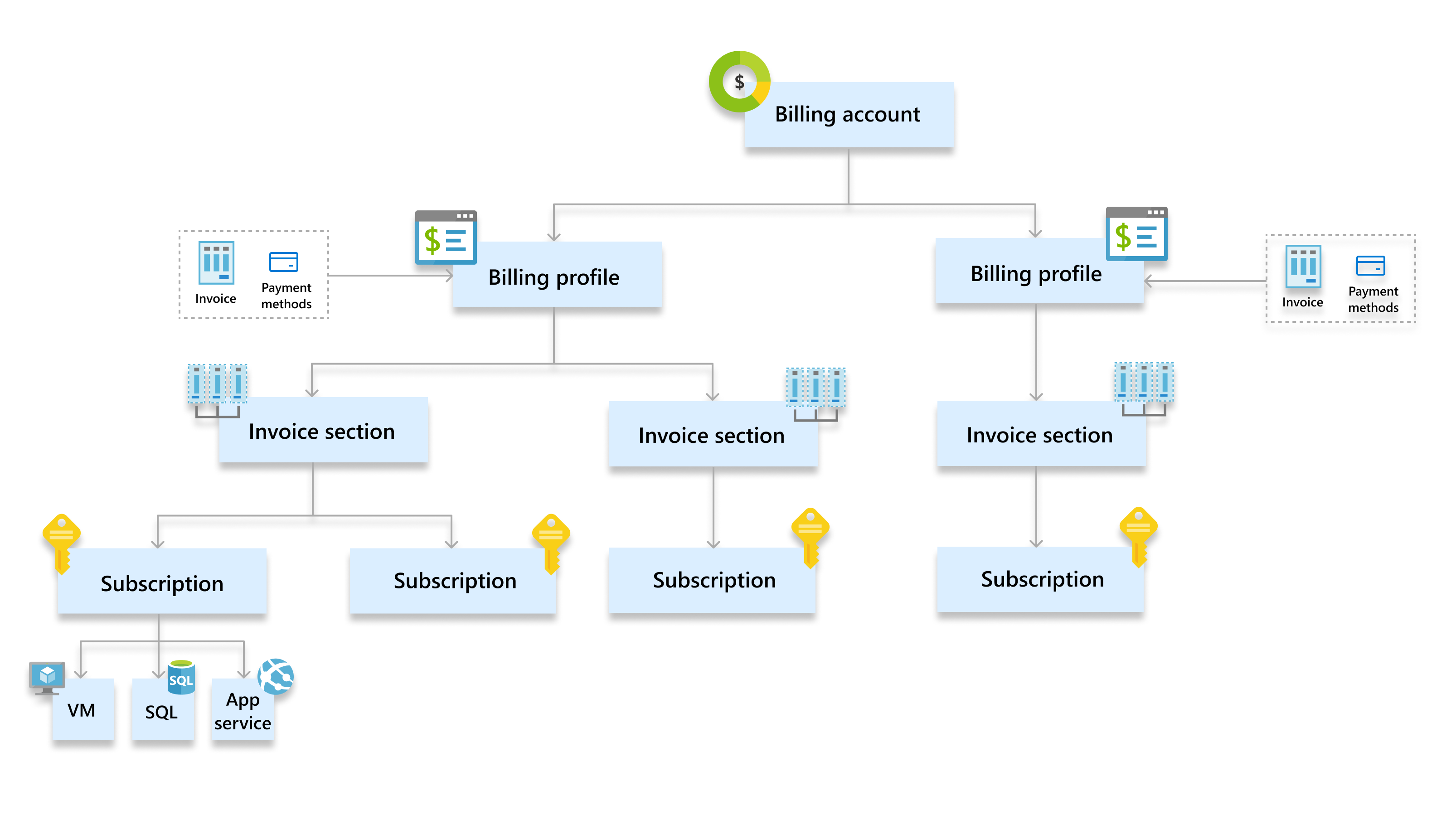
Compte de stockage
https://learn.microsoft.com/fr-fr/azure/storage/common/storage-account-overview
La gestion se fait sur le portail Azure, section “Comptes de stockage”.
Il faut créer un compte de stockage (qui lui-même doit appartenir à un groupe de ressources).
Les performances du compte de stockage (standard ou premium) est défini définitivement à la création du compte.
Le compte de stockage est protégé par 2 clés, “storage account key”. On peut les voir sur le portail Azure, dans le compte de stockage -> Sécurité + réseau (colonne de gauche) -> Clé d’accès.
Ces clés donnent un accès admin complet à l’ensemble des partages et données du compte de stockage.
Pay-as-you-go ou provisionned
https://learn.microsoft.com/en-us/azure/storage/files/understanding-billing
Calculateur de coûts ici :
https://azure.microsoft.com/en-us/pricing/calculator/
Il y a 2 modèles de facturation pour les partages Azure Files :
- le modèle provisionné v2 (le v1 est uniquement pour les storage premium, en SSD) (on définit d’avance une capacité max de stockage, des IOPS et de la bande passante, et le coût est fixe)
- le modèle à l’usage, où on paye chaque Go de stockage, chaque transaction, et chaque Mo de transfert
Le modèle de facturation est défini au niveau du compte de stockage, et sera visible dans ses propriétés (Kind : StorageV2 pour du PAYG, FileStorage pour du provisionné).
Cependant, pour les modèles provisionnés, le décompte de l’usage des ressources est fait pour chaque partage. C’est lorsqu’on déploie un partage que l’on commence à être facturé.
Pour des volumes de données faibles, le modèle PAYG peut être intéressant, mais il revient vite cher s’il y’a du volume de données (~ 300€/mois pour 2.7 To de données en cool storage dont le seul accès est la sauvegarde quotidienne ; en cool storage, le coût des transactions est vite important ! )
Le modèle provisionné peut vite être + intéressant, mais il a des quantités minimum (32Go, 500IOPS, 60MiB/s) qui induisent des coûts fixes, avec un minimum de ~30€/mois pour chaque partage.
Il est possible d’augmenter les performances du partage à tout moment. Pour ça :
Comptes de stockage -> sélectionner -> File shares -> ... (au bout de la ligne du partage) -> Change size and performance
On peut également diminuer le provisonnemnt, mais seulement 1 fois/24h.
Redondance
https://learn.microsoft.com/fr-fr/azure/storage/common/storage-redundancy
LRS : 3 copies dans le même datacenter
ZRS : 1 copie dans chacun de 3 datacenter différents (dans la même région primaire)
GRS : LRS en zone primaire + LRS en zone secondaire
GZRS : ZRS en zone primaire + LRS en zone secondaire
Le niveau de redondance est défini au niveau du compte de stockage, mais il pourra être changé par la suite. Pour ceci :
Storage accounts -> sélectionner -> Data management -> Redundancy
et choisir la nouvelle redondance.
Attention MS prévient que ça peut mettre plusieurs jours (ou semaines !) pour démarrer.
Zones de disponibilité :
https://learn.microsoft.com/fr-fr/azure/reliability/availability-zones-overview?tabs=azure-cli#azure-regions-with-availability-zones
Partages
Une fois le compte de stockage créé, on peut créer des partages (Portail -> Comptes de stockage -> Partages de fichiers puis + Partage de fichiers). Le nom ne peut pas contenir de majuscule.
Chaque partage a son propre niveau de performance (froid, chaud, optimisé pour les transactions).
Celui-ci peut se changer par la suite si besoin.
MS conseille, s’il y a des gros volumes à transférer, de commencer par le niveau optimisé pour les transactions le temps de la migration, puis de repasser à un autre niveau après.
Chaque partage a ses paramètres de sauvegarde.
Suppression réversible (Soft delete)
Concerne uniquement la suppression d’un partage (et non de fichiers dans ce partage).
Si activé, lorsqu’un partage est supprimé, il reste “dans la corbeille” pendant un temps (configurable).
Activé au niveau du compte de stockage, pour tous les partages lui appartenant.
Article chez MS
Les partages dans l’état soft-delete sont facturés selon le modèle de facturation choisie pour le compte de stockage (ils comptent comme s’ils étaient actifs).
Paramètres SMB
Récap chez Microsoft
L’accès SMBv3 est ok pour Windows 10 et Debian Bullseye. Les paramètres SMB sont identiques pour tous les partages au sein d’un compte de stockage.
Accéder au partage Azure Files
Article chez Microsoft
Obtenir l’UNC
Ça devrait toujours être \\nomducomptedestockage.file.core.windows.net\nom-du-partage .
Pour le vérifier :
Azure Portal -> Comptes de stockage -> Sélectionner le compte de stockage souhaité -> Partage de fichiers (colonne de gauche du panneau central) puis clic sur Connecter
Cela donne un script, dans lequel on trouve l’UNC.
On y voit aussi la clé de sécurité, derrière le /pass=
Connexion via clé
Si on veut établir la connexion manuellement, on peut ajouter les informations de connection dans Panneau de configuration -> Comptes d'utilisateur -> informations de connexion Windows (ou à la volée lors de la connexion) :
- Adresse :
nomducomptedestockage.file.core.windows.net
- Utilisateur :
nomducomptedestockage (ou localhost\nomducomptedestockage )
- Mot de passe : clé du compte de stockage
Il est bien sûr possible d’automatiser le déploiement de ce partage via GPO (ou Intune).
Depuis Linux
smb://nomducomptedestockage.file.core.windows.net/nom-du-partage
Mêmes utilisateurs et mot de passe. “Domaine” non-pertinent.
Authentification/autorisations
Article chez Microsoft
L’accès au partage se fait :
- soit par la “storage account key” (donne un accès complet admin à tous les partages du compte de stockage)
- soit par un accès basé sur l’identité (IAM)
Si on veut utiliser l’IAM, il est bien de commencer par vérifier que le montage fonctionne en utilisant la storage key, pour s’assurer du bon fonctionnement de la partie réseau sans s’occuper de la partie authentification.
Si on veut utiliser l’IAM, il faut le paramétrer. Un paramétrage sur le compte de stockage lui-même est nécessaire (chaque entité doit avoir les droits d’accès au compte de stockage pour accéder à un partage inclus dedans).
Ce paramétrage se fait sur le portail, dans Compte de stockage -> le choisir -> Access Control (IAM) -> Add -> Add role assignment .
On recherche “SMB”, puis on choisit le rôle “Storage File Data SMB Share Contributor” (pour un contributeur simple, qui peut modifier les fichiers).
On y affecte ensuite l’entité qui doit bénéficier de ce rôle (un groupe, un utilisateur).
Si on souhaite pouvoir modifier les ACL directement sur les dossiers/fichiers, depuis l’explorateur Windows, il faut accorder le rôle “Collaborateur à privilèges élevés de partage SMB des données du fichier de stockage”.
Chaque partage de ce compte héritera de cette IAM. Il est possible de surcharger chacun des partage avec d’autres droits (par exemple refus d’accès ?).
Il y a 3 méthodes d’authentification auprès d’une “source AD”, chacune avec ses spécificités.
Auprès d’un AD local (AD DS)
Il est nécessaire de pouvoir contacter ce DC local lors de l’établissement de la connexion au partage.
Ce DC local peut éventuellement être hébergé dans le cloud, avec accès via un VPN.
Disponible seulement pour les utilisateurs hybrides (synchronisés depuis le DC local vers Entra ID).
Introduction - MS
Activation - MS
Entra Domain Services (Entra DS, anciennement Azure AD DS)
Il s’agit d’un domaine géré (managé) par MS, qui fournit entre autres des fonctionnalités de DC et de GPO.
Il semble plutôt fait pour la gestion centralisée de serveurs virtuels, et il ne peut être contacté que via la connexion à un VPN.
Prend en charge les utilisateurs hybrides ainsi que cloud-only.
Les clients (postes utilisateurs) ne peuvent pas être Entra-joined ou Entra-registered.
les clients doivent être joints au domaine hosté pour que tout soit automatisé.
Il est toutefois possible de monter le partage depuis un poste non-joint à un domaine en fournissant des IDs explicites.
Récap chez Microsoft
Activation
Entra Kerberos
C’est une authentification directement auprès d’Entra, uniquement pour les utilisteurs hybrides (synchronisés depuis un DC local).
L’accès peut se faire sans besoin de connexion au DC (sauf pour régler les droits d’accès, là une connexion au DC sera nécessaire).
Les postes clients doivent être Entra-joined ou Entra-hybrid-joined ; pas ok si joints à Entra DS ou si joints uniquement à un AD local.
Détails sur mon memo
Migration des données
https://learn.microsoft.com/fr-fr/azure/storage/files/storage-files-migration-overview
Plusieurs méthodes possibles ; par exemple :
- simplement avec robocopy d’un lecteur à l’autre
- avec Azure Storage Mover
- avec Azure Files Sync
Azure Files Sync
https://brouillons.raphaelguetta.fr/post/azure-files-sync/
Pour synchroniser un serveur local avec un partage Azure Files Sync
https://learn.microsoft.com/en-us/azure/storage/file-sync/file-sync-planning
Possible de faire de la synchro simple.
Possible aussi de donner au server local un rôle de cache, les clients s’adressant à lui et lui échangeant avec Azure.
Azure Storage Mover
https://learn.microsoft.com/en-us/azure/storage-mover/service-overview
Capable de gérer des gros volumes de données.
Transfère les metadonnées.
Requiert la création sur Azure d’une ressource Azure Storage Mover
Requiert ensuite la création d’un agent (apparement c’est une VM)
Coût
https://azure.microsoft.com/fr-fr/pricing/details/storage/files/#pricing
Il y’a plusieurs choses distinctes qui sont facturées : stockage utilisé, transactions (lecture/écriture de données), metadonnées, backups, snapshots etc…
Facturation provisionnée (espace pré-payé, qu’il soit utilisé ou non)
Facturation à l’usage pour les modes standard (optimisé pour les transactions, chaud, froid).
Le stockage est de moins en cher quand on descend dans les gammes (optimisé pr transactions -> chaud -> froid)
Les transactions sont de + en + chères quand on descend dans la gamme.
Il est possible de changer le niveau de chacun des partages à tout moment. Ceci entraîne toutefois des transactions donc de la facturation.
Sauvegarde
https://learn.microsoft.com/en-us/azure/backup/azure-file-share-backup-overview
https://memo.raphaelguetta.fr/post/azure-files-backup
Disques managés
disques virtuels attachables à une VM azure en tant que disque local
https://azure.microsoft.com/fr-fr/pricing/details/managed-disks/
en HDD, 8To = 300€/mois
Montable sur plusieurs serveurs virtuels ?